AI adoption in fintech engineering has stopped being a pilot question. According to the Cambridge Centre for Alternative Finance 2026 Global AI in Financial Services Report, software engineering is now among the most common AI use cases in financial services, deployed at pilot stage or beyond by 75% of institutions, and 52% of firms are already actively adopting agentic AI. Fintechs are moving faster than incumbents on both counts.
We recently joined a closed roundtable of CTOs and VPs of Engineering from fintech, edtech, insurance, and credit-data companies across the US and Europe. Nobody asked “should we adopt AI agents?” The questions were harder: how do we keep AI-written code out of regulated production paths until it’s verified, what do we tell a board that wants headcount cuts, and what happens when token prices double.
This article is a field report from that conversation, combined with what we observe across our own AI transformation engagements with regulated fintech clients. It covers where engineering teams actually stand in mid-2026, why AI adoption growth in fintech has outpaced governance readiness, why compliance rather than model quality now sets the pace, and the bets engineering leaders are making for the next 12 months.
Quick Answer: AI adoption in fintech engineering has moved beyond pilots. Coding agents now support development, QA, documentation, and operational workflows, while engineers shift toward architecture, review, and production accountability. The main constraint is no longer model quality but governance: what AI can access, who can approve AI-generated code, how compliance is checked, and how model costs are controlled. The strongest fintech teams follow one rule: AI and agents execute, humans decide.
Key Takeaways:
- AI adoption in fintech engineering is already moving into daily SDLC workflows.
- The biggest risk is not bad code, but ungoverned code entering regulated production paths.
- CTOs should measure accepted output, human override rate, compliance findings, and customer-facing bugs.
- Non-engineers can prototype with AI, but engineering should own production code.
- Fintech teams need contingency plans for model cost, access, and vendor dependency.
Who this article is for: CTOs, CPOs, and AI transformation leaders at payment companies, EMIs, and other regulated fintechs who are scaling AI in their SDLC while managing board pressure and compliance risk.
Content:
- Where Fintech Engineering Teams Actually Are with AI
- Why Compliance, Not Model Quality, Sets the Pace
- How to Handle Board Pressure to Cut Teams and Move Faster
- What to Measure Beyond Speed
- What Contingency Plans Do CTOs Have for Model Cost and Risk?
- A Working Governance Model: Agents Execute, Humans Decide
- How Kindgeek Can Help
- Conclusion
- FAQ
Where Fintech Engineering Teams Actually Are with AI
The honest answer from the roundtable: AI adoption in fintech engineering is further along than most industry commentary suggests, and more unevenly distributed than vendor marketing admits.
Several patterns repeated across companies of very different sizes:
AI writes most of the code
One growth-stage CTO reported that 80% or more of his team’s code is now AI-generated, with engineers acting as architects and reviewers who, in his words, spend their day “arguing with the model to get it written right.” Another team has product managers shipping pull requests directly.
QA is being absorbed into engineering
The same CTO dissolved his dedicated QA team over a year ago. AI writes the automated tests, performs click-through testing, and engineers own the quality of what they build instead of handing bugs to someone else. He reports fewer production bugs than at any point in five years. We see a similar shift in our own delivery practice, which we described in how we built AI-driven QA into fintech CI/CD pipelines.
Agents handle operations, not just code
First-line incident response at one voice-AI company is an agent that reads observability logs and the codebase, then posts a root-cause hypothesis before a human engineer opens the ticket. Another team runs an agent that answers customer-success questions from Slack.
The bottleneck moved upstream
Engineering got fast; product discovery, customer research, and compliance review did not. Several leaders described engineers waiting on inputs for the first time in their careers. One admitted he stopped buying extra tokens because running out became a natural rate limiter.
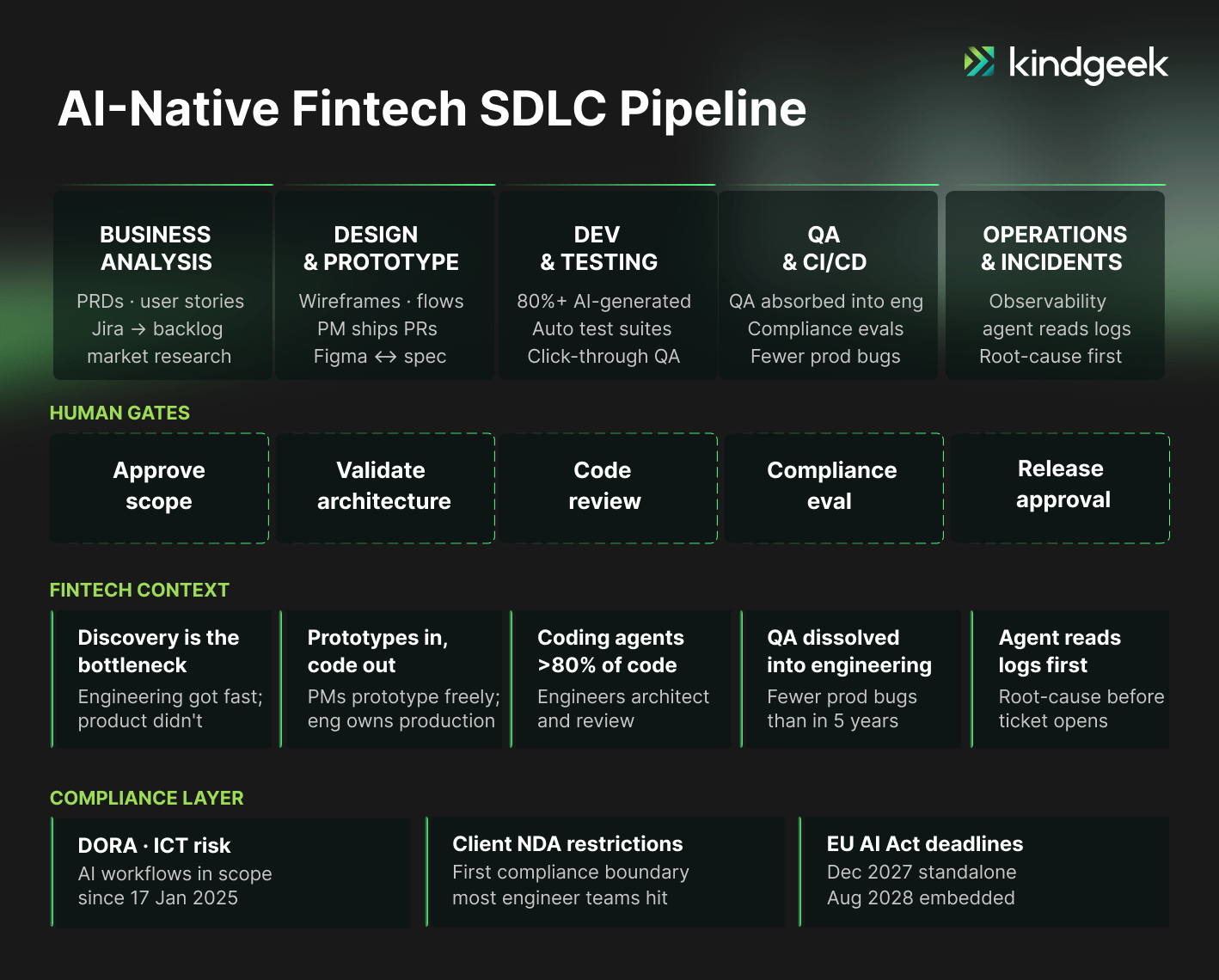
At Kindgeek, we run AI across the full SDLC: business analysis, design, development, QA, DevOps, and project management. We are into scaling. What we have deliberately not done is delegate scope, architecture, or production decisions to agents. That distinction, between AI as executor and humans as decision-makers, turned out to be the central theme of the entire roundtable.
Why Compliance, Not Model Quality, Sets the Pace
Every leader in a regulated industry, fintech, insurance, credit data, education, said a version of the same thing: the models are good enough; the governance is not.
The most vivid example came from a CTO at an on-chain personal finance company. A new designer, given a coding agent, built a polished, working app over a few days. The CEO saw it and wanted it in production. The CTO blocked it: the app looked finished, but no engineer had reviewed it for security flaws that could lose users real money. As one participant put it, if a vibe-coded internal tool corrupts your fitness-tracker data, nobody cares. When it moves money, everything changes.
Based on what we observe across our AI transformation engagements, companies rarely fail at AI because they lack better models or more agents. They fail upstream: data that isn’t structured or owned by anyone, unclear API ownership, change-management gaps, and occasionally quiet sabotage from teams that feel threatened. Model selection is the easy 20%.
The EU AI Act (Regulation (EU) 2024/1689) entered into force in 2024. In May 2026, the Council and Parliament reached a provisional agreement on targeted AI Act simplification measures, including delayed application dates for high-risk AI system rules: 2 December 2027 for standalone high-risk systems and 2 August 2028 for high-risk systems embedded in products.
Meanwhile DORA has applied to EU financial entities since 17 January 2025, which means AI-dependent engineering workflows are no longer only an internal productivity question. If they affect delivery, incident response, third-party tooling, or operational continuity, they become part of the institution’s ICT risk and resilience picture.
And regulation is only half of it. Contracts move faster than law: we now receive RFPs for digital transformation work whose NDAs explicitly prohibit using AI tools on client data. Client agreements, not the AI Act, are the first compliance boundary most engineering teams hit.
| Problem | What it means | How to fix it |
|---|---|---|
| Non-engineers shipping AI-written code | Working-looking apps with unreviewed security and compliance flaws reaching production | Hard rule: prototypes and problems flow to engineering; code does not. Guardrailed zones where PMs/designers can safely commit |
| AI outputs touching regulated data | Breach of client NDAs, GDPR exposure, DORA operational-risk findings | Data classification before agent access; local or VPC-deployed models for sensitive workloads; audit trail on every agent action |
| Probabilistic agents taking actions | Untraceable decisions in money-moving flows | Tiered guardrails: deterministic rules at the agent level; generative agents restricted to advisory roles, never direct action |
| Compliance team outside the AI loop | Engineering ships faster than compliance can review; findings arrive post-release | Embed compliance evals into CI/CD; train compliance staff on AI workflows instead of routing everything through manual review |
The teams handling this well don’t slow down AI adoption. They draw the production line precisely and automate the path to it.
How to Handle Board Pressure to Cut Teams and Move Faster
Every leader at the table reported the same pressure, in nearly the same words: boards and investors read the “we replaced our engineering team with agents” posts and ask why headcount isn’t shrinking.
Three response patterns emerged, and they are not mutually exclusive:
1. The three-buckets conversation
One enterprise AI architect frames AI initiatives in three buckets: productivity tools and copilots; existing processes with AI components; and fully reimagined processes. Boards consistently want bucket three before the organization has done buckets one and two. Naming the buckets explicitly, with risks attached to each, converts “why aren’t we there yet” into a sequencing discussion with shared ownership of risk.
2. The justify-the-role rule, honestly applied
Several companies adopted the policy: to open a new role, explain why AI cannot do the job. Applied honestly, it cuts both ways. The same CTO who dissolved QA and automated most of his SDLC told his board he cannot shrink the team, because AI exposed how much more the company wants to build. The bottleneck moved upstream; it did not disappear.
3. The talent reality check
There is a counter-current: one CTO argued that a seven-person mobile team maintaining a single app is indefensible in 2026, when one strong engineer with a coding agent can ship the same app. He is right about the math and the roundtable pushed back on the hiring market: the engineer who can replace a team must own business context, customer needs, design judgment, and architecture simultaneously. We receive requests for exactly this profile weekly. These people are rare, expensive, and the industry is still mid-transition in producing them. Plan for the math; budget for the reality.
The honest position for a CTO is neither “AI changes nothing” nor “we’re cutting half the team.” It is: capacity per engineer is up sharply, ambition has grown faster than capacity, and the limiting factors are now product decisions, compliance review, and senior judgment, none of which the current generation of agents supplies.
What to Measure Beyond Speed
Velocity stopped being a useful headline metric the moment AI made everyone fast. Understanding AI adoption rates in fintechs requires looking beyond throughput to how much of that output is safe to ship. The roundtable converged on a different set:
- Accepted output, not raw output
What share of AI-generated work, code, tickets, designs, makes it into production without rework? This is the metric we track internally at Kindgeek, and it separates teams that ship from teams that generate. - Human override rate
How often do people have to overrule agent decisions? A falling override rate is the leading indicator that an agent is ready for more autonomy; a stable or rising one means it isn’t. - Compliance and security findings
Regulatory breaches, audit findings, and security issues traced to AI-assisted changes. For payment companies this is the metric the board should actually see. One CTO described building compliance evaluations that score AI outputs continuously, the same way you’d run a test suite. - Bugs reaching customers and idea-to-production lead time
The classic engineering health metrics still apply, measured honestly rather than against deadlines that force errors. - Adoption by role
Whether BAs, PMs, designers, and QA engineers, not just developers, use AI tooling at full capacity. Uneven adoption is where the upstream bottleneck hides.
One metric drew unanimous skepticism: token consumption as a proxy for productivity. Token prices and limits are set by vendors and can change overnight, which makes the number meaningless as a performance measure, though essential as a cost-control one.
What Contingency Plans Do CTOs Have for Model Cost and Risk?
The closing bets at the roundtable clustered around one anxiety: dependence. Engineering organizations have rebuilt their SDLC around frontier models owned by a handful of vendors, and every leader at the table expects token costs to rise and access terms to tighten. Several had already felt the sticker shock between their original contracts and renewals.
The contingency playbook that emerged has four layers:
1. Tiered model strategy
Route tasks to the cheapest model that can do them: small and mid-size models for routine work, frontier models reserved for the problems that need them. One architect described treating GPU inference as a first-class platform constraint, with graceful degradation, cached responses and reduced functionality, instead of hard failures.
2. Local models for sensitive and routine workloads
Multiple CTOs are actively evaluating open-weight models on local hardware. They are slower and weaker than frontier models, but for internal MVPs, cost optimization, and data that contractually cannot leave the organization, “good enough and always available” beats “best and metered.” We use secure on-premise machines for exactly this class of internal work.
3. Hybrid handoff
One leader builds primarily with a local model and hands off only the hardest steps to a frontier API, then returns. This pattern keeps cost and data exposure low without giving up peak capability.
4. Provider-agnostic architecture plus strategic partnership
Don’t hard-wire one vendor into your workflows; keep a second provider warm. At the same time, formal partner status with your primary vendor is a hedge in the other direction: priority access and better terms if capacity tightens. We pursue both tracks simultaneously, and we’d argue any company whose delivery depends on model access should too.
A separate bet worth recording: several leaders expect a wave of consolidation among thin-wrapper AI startups within 12–18 months, as model vendors absorb their use cases natively. The practical consequence for engineering leaders is a build-versus-buy shift: tools that are a prompt and a UI on top of someone else’s model are increasingly safer to build in-house than to procure.
A Working Governance Model: Agents Execute, Humans Decide
Pulling the threads together, here is the governance baseline we apply in our own SDLC and recommend to fintech clients scaling AI adoption in fintech engineering. It reflects the same engineering discipline we described in our guide to fintech product engineering, extended to agent workflows:
- One principle, stated publicly: AI and agents execute; humans decide. No agent owns scope, architecture, or a production release.
- A production line everyone can see. Define which repositories, services, and data classes are open to AI-assisted changes by non-engineers, which require engineering review, and which (money movement, KYC/AML, ledger logic) require senior review regardless of who or what wrote the code.
- Prototypes in, code out. Product, design, and leadership prototype freely with AI tools, and hand engineering problems and prototypes, not pull requests. This preserves the genuine value of non-engineer prototyping without the production risk.
- Tiered guardrails on agents. Deterministic rules where actions are taken; probabilistic agents in advisory roles only. Every agent action logged and attributable, which DORA-era supervision will expect anyway.
- Compliance in the pipeline. Evals for regulatory and security constraints run in CI/CD, not in a quarterly review. AI deployments touching client data get explicit sign-off against client NDAs, not just internal policy.
- An exit ramp. A documented plan for model degradation, restriction, or repricing: tiered models, a local fallback for sensitive workloads, and no single-vendor hard dependency.
If your data layer isn’t ready for this, fix that first. In our experience, data readiness, ownership, and change management determine AI transformation outcomes far more than model choice.
How Kindgeek Can Help
Kindgeek is a fintech-specialized engineering company: 200+ engineers, 100+ fintech projects since 2015, and platforms processing €10B+ annually, built under ISO 9001 and ISO 27001-certified processes. We run AI across our own SDLC at scale, under the same human-in-the-loop governance described above, so the advice we give clients is the playbook we operate daily.
For engineering leaders under pressure to move faster on AI without compromising a regulated product, we work in two modes. Our AI transformation services cover the unglamorous foundations that determine success: data readiness, agent governance, compliance-aware workflow design, and change management across roles. And when AI-assisted development has already produced code you’re not sure you can trust in production, our software audit services give you an engineering-grade review of security, architecture, and compliance before it ships. You can see how we’ve applied this discipline for payment companies, EMIs, and neobanks in our case studies.
If your board wants AI-driven velocity and your compliance team wants control, those goals are compatible. We can help you build the SDLC that delivers both.
Conclusion
The state of AI adoption in fintech engineering in mid-2026 is easy to misread from the outside. The loud story is automation and headcount; the real story, the one CTOs tell each other behind closed doors, is governance. Models are commoditizing. What separates teams now is whether their data is ready, whether their production line is drawn precisely, whether compliance runs in the pipeline instead of after it, and whether anyone has a plan for the day token prices double.
The principle that held across every regulated company at the table is the one we run our own SDLC on: agents execute, humans decide. Speed is no longer the differentiator, because everyone is fast. Verified, compliant, accountable speed is.
If your team is scaling AI-assisted development and the question keeping you up is “what reaches production, and who answers for it,” Kindgeek can help you build the governance, data foundations, and delivery pipeline to scale with confidence. Talk to us about where your AI adoption actually stands.
What is the best AI governance model for fintech engineering?
The model that consistently works in regulated environments is: AI and agents execute while humans decide. In practice this means tiered guardrails (deterministic rules at agent level, generative agents restricted to advisory roles in money-moving flows), a visible production line defining which code requires engineering or senior review regardless of who wrote it, compliance evals embedded in CI/CD rather than run quarterly, and a documented contingency plan for model access and cost risk. The governance model should be public within the engineering organization so everyone understands the boundary between autonomous AI execution and mandatory human approval.
How do fintech teams use AI in the SDLC?
Leading fintech engineering teams deploy AI across the full software development lifecycle: coding agents write and review code, AI tools generate and run automated tests, documentation is produced automatically from code and tickets, and agents monitor production observability logs to surface root-cause hypotheses. Business analysts and product managers use AI for discovery and requirements drafting. The consistent pattern is that AI handles execution at each stage while engineers own the decisions and production sign-off.
How should fintech teams manage AI-generated code in regulated environments?
Through a layered governance model: classify repositories and services by risk level, require senior engineering review for all AI-generated code touching payment flows, KYC/AML logic, or ledger operations, run automated compliance and security evals in the CI/CD pipeline before any merge, and maintain an audit trail on every agent action. The goal is to define a precise production line that AI-generated code must cross before it ships.
What is a realistic contingency plan if model costs rise sharply?
Four layers: route routine tasks to cheaper or smaller models; maintain a local open-weight model option for sensitive and internal workloads; design workflows to be provider-agnostic so you can shift between vendors; and pursue formal partnership status with your primary vendor for priority access and pricing. Test the fallback path before you need it.
How should a CTO answer board pressure to cut the engineering team because of AI?
With data on where the bottleneck actually sits. In most organizations, AI multiplied engineering capacity and ambition grew faster still, moving the constraint upstream to product decisions and compliance review. A defensible position is a hiring rule (“justify why AI can’t do this role”) combined with evidence that current headcount is the floor for the roadmap the board itself approved.
What metrics should CTOs use to track AI adoption in fintech?
The four that matter most are: (1) the share of AI-generated work that reaches production without rework; (2) how often engineers override or redo agent decisions; (3) compliance and security findings attributable to AI-assisted changes; and (4) idea-to-production lead time for features initiated by AI-assisted discovery or BA work. These are leading and lagging indicators of whether AI adoption is improving the delivery system or just making it faster to generate unshippable work.
Does the EU AI Act delay mean fintechs can postpone AI governance?
No. The May 2026 Digital Omnibus agreement defers high-risk obligations for standalone systems to December 2027, but other AI Act provisions continue to apply on the original schedule, DORA has applied since January 2025, and client contracts increasingly impose stricter AI restrictions than regulation does. Treat the delay as preparation time.
Should non-engineers be allowed to ship AI-generated code?
Not into production systems that move money or handle regulated data. The pattern that works is “prototypes in, code out”: product managers and designers prototype freely with AI tools and hand engineering a working prototype plus a problem statement, while engineers own everything that ships. Some teams additionally define guardrailed, low-risk code areas where non-engineers can commit safely.
How much production code is actually written by AI in 2026?
It varies widely by company and risk profile. Engineering leaders at growth-stage companies report 80% or more of new code being AI-generated, with engineers reviewing and architecting rather than typing. Regulated teams typically run lower shares in critical paths such as payment processing and ledger logic, where senior human review remains mandatory regardless of who wrote the code.